
Как работает клиент сервер
Содержание:
Сегодня речь пойдет о так называемом взаимодействии Клиент-Сервер, так как практически все программное обеспечение построено на данном принципе. А как Вы помните, что у нас сайт для начинающих программистов и понимание данного взаимодействия обязательно для новичка в программирование. Поэтому в данном материале мы рассмотрим, что это такое и для чего это нужно.
Как я уже сказал, если Вы хотите стать программистом то Вы должны понимать принцип данного взаимодействия, потому что хотите Вы или нет, Вам придется столкнуться с этим, так как это встречается практически везде, например все сайты в Интернете построены на этом, все программы которые используют базу данных, сюда также можно и отнести и автоматическое обновление программ, и многое другое.
Теперь поговорим подробней. Что такое взаимодействие Клиент-сервер? Это взаимодействие двух программных продуктов между собой, один из которых выступает в качестве сервера, а другой соответственно в качестве клиента. Клиент посылает запрос, а сервер отвечает ему. А что такое клиент и что такое сервер? Спросите Вы. Клиент это программная оболочка, с которой взаимодействует пользователь. А сервер это та часть программного обеспечения, которая выполняет все основные функции (хранит данные, выполняет расчеты). Другими словами, пользователь видит программу, которая, допустим, работает с какими-то данными, которые хранятся в базе данных, тем самым он видит всего лишь интерфейс этой программы, а все самое основное выполняет сервер, и процесс когда пользователь оперирует данными через интерфейс программы, при котором клиентская часть взаимодействует с серверной, и называется Клиент-Сервер. В качестве клиента не обязательно должен выступать интерфейс, который видит пользователь, в некоторых случаях в качестве клиента может выступать и просто программа или скрипт, например, данные на сайте хранятся в базе данных, соответственно скрипты, которые будут обращаться к базе данных и будут являться клиентом в данном случае, хотя и сами эти скрипты являются сервером для клиентской часть сайта (интерфейса).
А для чего это нужно?
Это лучше объяснить на примере.
Допустим, Вы написали программу, которая умеет работать с некими данными и установили ее пользователю, все замечательно работает, пока другой пользователь не скажет, а я хочу такую же программу, но чтобы данные у нас были одни, и при редактировании одним пользователем другой мог увидеть это изменение. И для этого Вам необходимо сделать какую-то базу данных доступ, к которой можно получить через интерфейс Вашей программы, причем данная база должна располагаться на отдельном сервере, для того чтобы все пользователи могли получить к ней доступ, конечно, которым Вы разрешите.
И тем самым всем пользователям, которым нужна эта программа, Вы устанавливаете только клиентскую часть и настраиваете взаимодействие с сервером. В данном случае подразумевается, что Вы на сервере установите СУБД (Система управления базами данных).
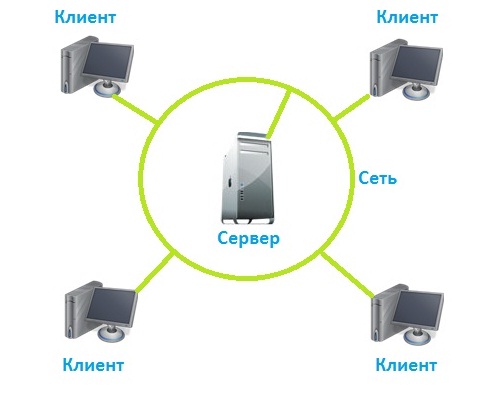
Где под клиентом понимается клиентская часть приложения, которая взаимодействует с серверной частью приложения по средствам сети.
Все сайты в Интернете располагаются где-то на серверах (хостинге), а Вы соответственно хотите получить доступ к ним и для этого используете браузер и в данном случае браузер и есть клиент, а файлы на хостинге сервер. Если разбирать отдельно взятый сайт, то здесь также присутствует данное взаимодействие, к примеру, в браузере Вы видите всего лишь интерфейс приложения и при любых Ваших действиях на этом сайте данный интерфейс будет отправлять запрос серверу который выполнит все что Вы запросили и пришлет ответ, а клиент в свою очередь отобразит этот ответ, для того чтобы пользователь смог увидеть его.
Другими словами принцип клиент-сервер основан на том, что клиент отправляет запрос серверу, а сервер отвечает ему. И данные запрос-ответы могут выглядеть по-разному, могут использоваться разные протоколы, такие как tcp/ip, http, rdp и много других.
Теперь надеюсь, стало понятно, что такое Клиент-сервер, теперь давайте немного поговорим о том, как лучше реализовывать данное взаимодействие.
Как уже говорилось выше, если Вы захотели хранить данные в базе данных то лучше всего использовать СУБД, такие как MSSql, MySQL, Oracle, PostgreSQL так как данные СУБД предоставляют огромные возможности для серверной разработки. Так как, когда Вы будете разрабатывать программное обеспечение по такому принципу, Вам лучше всего четко разграничить клиент и сервер, т.е. клиент выполняет только роль интерфейса, из которого можно будет посылать запросы серверу на запуск процедур или функций, а соответственно сервер будет выполнять эти процедуры и функции и посылать результат их выполнения клиенту, предварительно, конечно же, Вы должны будете написать эти самые процедуры и функции, что и позволяют делать данные СУБД. Этим Вы упростите разработку и увеличите производительность Вашего программного обеспечения. Поэтому запомните клиент, во всех случаях, при взаимодействии Клиент-Сервер должен выполнять только лишь функцию интерфейса, и не нужно на него возлагать какие-то там другие задачи (обработка данных и другое), все, что можно перенести на сервер переносите, а пользователю предоставьте всего лишь интерфейс.
В связи с этим пришло время поговорить о преимуществах данной технологии:
- Низкие требования к компьютерам клиента, так как вся нагрузка должна возлагаться на сервер и серверную часть приложения, в некоторых случаях можно значительно сэкономить затраты на приобретение вычислительной техники в организациях;
- Многопользовательский режим. Ресурсами сервера могут пользоваться неограниченное число пользователей, при том что данные располагаются в одном месте;
- Целостность данных. Вывести из строя компьютер клиента гораздо проще, и чаще встречается, чем компьютер, который выполняет роль сервера. Как Вы знаете, проблемы с компьютерами у пользователей встречаются достаточно часто, так как они сами их себе и создают.
- Внесение изменений. Проще внести изменения один раз в серверной части, чем вносить их на каждом клиенте.
Есть также пару недостатков :
- Для быстродействия требуется приобрести достаточно мощный сервер, но как было уже сказано выше, это может и окупится, за счет компьютеров пользователей;
- Выход из строя серверной части прекратит работу всех клиентов, в связи с этим возникает необходимость постоянного мониторинга серверной части.
Перед тем как заняться разработкой приложения Вы должны знать, на чем Вы это будете реализовывать, так как существуют разные технологии и языки, например, при взаимодействии с СУБД Вам придется изучить SQL, хотя бы основы SQL , но лучше, если Вы будете знать, как написать функцию или процедуру, так как без этого Вам не обойтись, ну если конечно не разделить обязанности между программистами, например, один специалист разрабатывает серверную часть, а другой клиентскую, так, кстати, все и делают, потому что сами понимаете, что все знать просто невозможно.
Или на примере сайта в Интернете, существуют как серверные языки программирования, например PHP так и клиентские, например JavaScript, поэтому, если Вы решили сами создать нормальный сайт в Интернете, то учтите, что Вам придется с этим столкнуться и проще говоря, Вы должны будете стать Web-мастером который должен знать ой как много:).
Как Вы уже поняли, что взаимодействие Клиент-Сервер используется практически везде, и можно сказать, сеть построена, для того чтобы пользователь, по средствам программного обеспечения, мог взаимодействовать с другими пользователями или удаленными ресурсами, так как все что Вы запрашиваете или отправляете по сети основано на взаимодействие запрос-ответ. Поэтому начинающий программист должен понимать данное взаимодействие и в последствие реализовывать его.
Файловые реляционные базы данных — это мощные настольные СУБД, включающие ядро и хранилище данных. Однако в условиях сложных бизнес-правил и повышенных требований к вычислительной мощности на первый план выходят клиент-серверные системы. На этом занятии мы познакомимся с компонентами клиент-серверных систем.
Изучив материал этого занятия, Вы сможете:
- перечислить преимущества клиент-серверных систем;
- описать стадии разработки клиент-серверного приложения;
- сопоставить различные типы клиент-серверных реализаций;
- выбрать клиент-серверную систему, подходящую для конкретной ситуации.
Архитектура клиент-сервер предъявляет специфические требования как к клиенту, так и к серверу. Программа, удовлетворяющая этим требованиям, может считаться клиент-серверным приложением, выполняющим распределенную обработку данных (рис. 6.5).
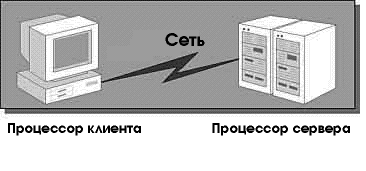
Рис. 6.5 Клиент, связывающийся с сервером по сети
Под распределенной обработкой понимается выполнение серверной частью программы запросов клиентской части. Серверная часть приложения обеспечивает хранение данных и их обработку, а клиентская часть передает серверу соответствующие запросы.
Преимущества клиент-серверных систем
- Клиент-серверный подход — модульный, причем серверные программные компоненты компактны и автономны.
- Поскольку каждый компонент выполняется в отдельном защищенном процессе пользовательского режима, сбой сервера не повлияет на остальные компоненты операционной системы.
- Автономность компонентов делает возможным их выполнение на нескольких процессорах на одном компьютере (симметричная многопроцессорная обработка) или на нескольких компьютерах сети (распределенные вычисления).
- Обязанность клиента, как правило, — предоставлять пользовательские сервисы и, прежде всего, пользовательский интерфейс, то есть средства для приема, отображения и редактирования данных, введенных пользователем, которые служат основой для запроса серверу. Кроме того, клиент можно настроить на обработку части данных, чтобы уменьшить нагрузку на ресурсы сервера.
Проектирование клиент-серверной системы
При разработке бизнес-приложения необходимо прежде всего проанализировать постановку задачи, чтобы понять, в каком направлении разрабатывать приложение. Дизайн проекта на всех стадиях разработки должен соответствовать поставленной задаче и требованиям конкретной бизнес-ситуации.
Клиент-серверное проектирование оптимизированной системы управления базой данных состоит из четырех стадий: концептуальной, логической, физической и перспективной (рис. 6.6). Этот путь от простого к сложному позволяет реализовать базу данных, предназначенную для решения конкретной задачи.
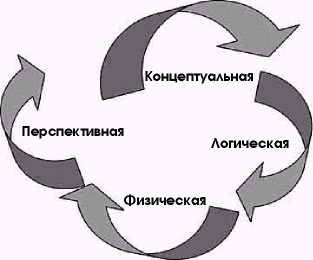
Рис. 6.6 Стадии проектирования клиент-серверной базы данных
На концептуальной стадии основное внимание уделяется сценариям использования приложения. Они должны отражать требования пользователей к решению конкретных проблем бизнеса. Здесь определяется бизнес-проблема и вырабатывается подход, отвечающий нуждам и требованиям пользователей.
На этой стадии на основе сценариев использования проектируются бизнес-объекты и необходимые сервисы. Логическая структура приложения представляет собой основу формальной модели для команды проектировщиков и базу для оценки различных вариантов физического решения.
На этой стадии проектируются физические компоненты для объектов и сервисов. Структура и дизайн компонентов должны отражать исходные бизнес-объекты и, естественно, сценарии использования. Дополнительные задачи на этой стадии — учет существующей инфраструктуры и технологий для минимизации риска и сокращения цикла разработки.
Сценарии перспективного использования приложения или системы — основа будущего расширения возможностей приложения. Они отражают мнение пользователей о будущем бизнес-решения и должны быть детализированы настолько, насколько это необходимо для понимания перспективы. Например, конкретное приложение может помимо текущего сценария платежей по чекам включать и перспективный — для расчетов по кредитным карточкам.
Пользователям, работающим в сети, часто требуется запускать приложения с сетевого сервера. Клиентские компоненты должны включать средства поддержки локальной информации (в том числе и информацию из локального реестра и локальных файлов) и средства, предоставляющие пользователю доступ к серверным компонентам.
В состав серверной части должны входить основные исполняемые файлы, библиотеки и все остальные файлы, необходимые для поддержки доступа пользователей по сети. Кроме того, надо изучить требования к ресурсам сервера и на их основе принять решение относительно аппаратной конфигурации, учитывая тип процессора (например, SQL Server поддерживает процессоры Alpha AXP, MIPS и 32-разрядные процессоры семейства Intel x86) и ресурс памяти (чем больше клиентов, тем больше потребуется ОЗУ для сохранения и увеличения быстродействия).
Клиент-серверная система управления базой данных может опираться на несколько типов распределения обязанностей между клиентом и сервером:
- «интеллектуальные» клиенты;
- «интеллектуальный» сервер;
- смешанные системы;
- многоуровневые системы. Схему реализации выбирают на основе анализа требований к:
- сетевому графику;
- ресурсам клиента и сервера;
- производительности базы данных.
Это один из самых распространенных методов реализации клиент-серверных приложений (рис. 6.7). «Интеллектуальному» клиенту можно доверить выполнение как бизнес-логики, так и сервисов представления данных.
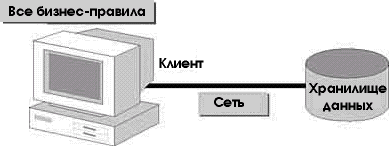
Рис. 6.7 Бизнес-логика реализована на клиенте
В этом случае функции сервера ограничены поддержкой собственно базы данных. Вся информация обрабатывается локально, что освобождает ресурсы сервера. Многие приложения, разработанные на Visual Basic, являются интеллектуальными клиентами.
Достоинства «интеллектуальных» клиентов
- Простота архитектуры, что облегчает разработку и сопровождение системы.
- Наличие хорошо известных и достаточно мощных средств разработки (например, Visual Basic 5.0).
- Клиент хорошо подходит для хранения текущей информации о состоянии, например первичного ключа записи, которую сейчас просматривает пользователь.
Недостатки «интеллектуальных» клиентов
- Выполнение бизнес-правил на клиенте иногда увеличивает сетевой трафик из-за необходимости передавать клиенту все данные для принятия решения на основе правил.
- Для модификации бизнес-логики необходимо повторное развертывание всех клиентов.
Перенеся все бизнес-правила на SQL Server, где они реализуются в виде хранимых процедур, Вы создадите «интеллектуальный» сервер (рис. 6.8). Роль сервера в такой клиент-серверной системе много шире простого хранилища файлов, доступных множеству пользователей сети. Интеллект сервера проявляется в способности выполнять команды (SQL-запросы) и возвращать результирующий набор данных.
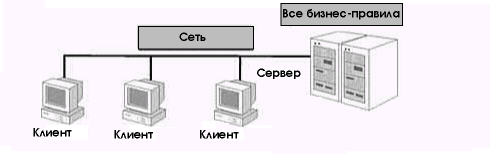
Рис. 6.8 Бизнес-логика реализована на центральном сервере
В двухуровневой системе с «интеллектуальным» сервером бизнес-логика и сервисы представления развертываются на сервере. В этом случае бизнес-логика обычно реализуется в виде хранимых процедур и триггеров БД, так что основная часть обработки выполняется на сервере, а не на компьютере-клиенте.
Достоинства «интеллектуальных» серверов
- Увеличение производительности: бизнес-логика выполняется в том же адресном пространстве, что и код доступа к базе данных, и, кроме того, тесно интегрирована с механизмом поиска данных SQL Server. Это означает, что данные не нужно перемещать или копировать перед обработкой, а значит, сетевой трафик минимизируется.
- На сервере легче обеспечивать целостность данных.
- При необходимости бизнес-логика модифицируется централизованно, без изменения клиентов.
Недостатки «интеллектуальных» клиентов
- Повышение требований к ресурсам сервера, где выполняются все запросы и манипуляции с данными.
- Ограниченный выбор средств разработки: хранимые процедуры, например, создают на языке Transact-SQL. Хотя SQL Server поддерживает вызовы кода, написанного на других языках, этот подход сложен и в общем случае менее эффективен, нежели разработка тех же функций на Transact-SQL.
В рамках двухуровневой реализации возможны и смешанные варианты, обладающие достоинствами как интеллектуальных серверов, так и интеллектуальных клиентов (рис. 6.9). Например, клиентский компонент смешанного решения, разработанный средствами Visual Basic, может вызывать хранимые процедуры SQL Server.
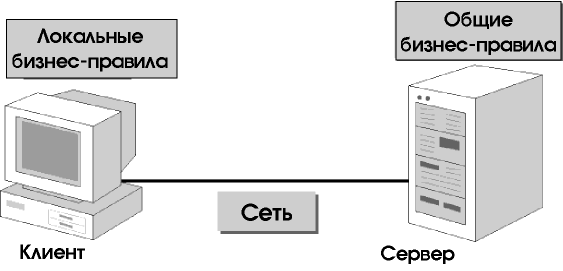
Рис. 6.9 Смешанные системы: интеллектуальные клиенты и интеллектуальный сервер
Достоинства смешанных систем
- Часть бизнес-логики может быть реализована в клиентской части.
- Серверный код (например, хранимые процедуры SQL Server) одновременно доступен многим клиентам, что снижает накладные затраты при выполнении однотипных запросов.
- Эффективность работы клиентов меньше зависит от сетевого трафика.
Недостатки смешанных систем
- Бизнес-логика распределена между клиентом и сервером.
- Модернизация приложения требует распространения новых версий клиентской части среди широкой аудитории.
Многоуровневая система (иногда ее называют трехуровневой) позволяет разделить пользовательский интерфейс, бизнес-правила и базу данных (рис. 6.10).
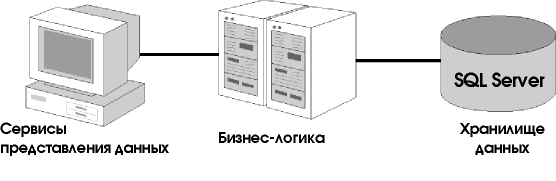
Рис. 6.10 Пользовательский интерфейс, бизнес-правила и база данных размешены отдельно
В многоуровневой системе бизнес-правила реализуются как отдельные библиотеки (DLL). Их (например, написанные на Visual Basic) можно разместить на сервере. Клиент, библиотеки и база данных составляют распределенные сервисы многоуровневой системы.
Сервис — это набор связанных функций, выполняющих определенные действия и/или предоставляющих информацию на основе взаимодействия с пользователем. Доступ к сервису обеспечивает интерфейс, инкапсулирующий его реализацию.
Сервисная модель — это метод рассмотрения приложения как набора средств или сервисов, которые удовлетворяют запросы клиентов. Моделирование программы в виде набора отдельных сервисов позволяет повторно использовать компоненты, предоставляет доступ к ним другим приложениям и помогает распределять их выполнение между несколькими компьютерами сети.
В типичных бизнес-приложениях возможны сервисы трех категорий.
Тип сервиса
Размещение
Назначение
Пользовательский
Клиент
Представление информации и доступа к функциям приложения, навигация, сохранение целостности и непротиворечивости пользовательского интерфейса
Бизнес-сервис
Сервер
Реализация основных стратегий, генерация информации на основе данных и поддержка целостности среды принятия бизнес-решений
Сервис данных
Сервер
Структуризация данных, их хранение, извлечение и поддержка целостности
Достоинства многоуровневых систем
Разделение компонентов интерфейса, бизнес-правил и хранения данных. Возможность применения интеллектуальных клиентов. Возможность применения сервисов.
Недостатки многоуровневых систем
Необходимы сервер и сеть. Увеличивается сетевой трафик.
Архитектура клиент-сервер позволяет разграничить обязанности сервера и клиентов, что делает ее одной из самых популярных моделей для систем масштаба предприятия. Клиент-серверное проектирование оптимизированной системы управления базой данных состоит из четырех стадий: концептуальной, логической, физической и перспективной. Реализация клиент-серверной системы управления базой данных может опираться на разные типы распределения обязанностей между клиентом и сервером. Среди них:
- «интеллектуальные» клиенты;
- «интеллектуальный» сервер;
- смешанные системы;
- многоуровневые системы.
Перевод не завершен. Пожалуйста, помогите перевести эту статью с английского.
Теперь, когда вы знаете цель и потенциальные преимущества программирования на стороне сервера, мы подробно рассмотрим, что происходит, когда сервер получает «динамический запрос» от браузера. Поскольку большая часть серверного кода веб-сайта обрабатывает запросы и ответы аналогичным образом, это поможет вам понять, что нужно делать при написании большей части собственного кода.
| Перед стартом: | Базовая компьютерная грамотность. Базовое понимание того, что такое веб-сервер. |
|---|---|
| Цель: | Изучить взаимодействие между клиентом и сервером на динамическом веб-сайте и в частности узнать, какие действия нужно произвести в коде серверной части. |
В обсуждении нет реального кода, поскольку мы еще не выбрали, какой веб-фреймворк мы будем использовать для написания нашего кода! Это обсуждение, тем не менее, очень актуально, поскольку описанное поведение должно быть реализовано вашим серверным кодом независимо от того, какой язык программирования или веб-фреймворк вы выбираете.
Web-серверы и HTTP (для начинающих)
Веб-браузеры взаимодействуют с веб-серверами при помощи протокола передачи гипертекста (HTTP). Когда вы кликаете на ссылку на странице, заполняете форму или запускаете поиск, браузер отправляет на сервер HTTP-запрос.
Этот запрос включает:
- Путь, определяющий целевой сервер и ресурс (например, файл, определенная точка данных на сервере, запускаемый сервис, и т.д.).
- Метод, который определяет необходимое действие (например, получить файл, сохранить или обновить некоторые данные). Различные методы/команды и связанные с ними действия перечислены ниже:
GET – получить определенный ресурс (например, HTML-файл, содержащий информацию о товаре или список товаров).
Веб-серверы ожидают сообщений с запросами от клиентов, обрабатывают их, когда они приходят и отвечают веб-браузеру через сообщение с HTTP-ответом. Ответ содержит Код статуса HTTP-ответа, который показывает, был ли запрос успешным (например, «200 OK» означает успех, «404 Not Found» если ресурс не может быть найден, «403 Forbidden», если пользователь не имеет права просматривать ресурс, и т.д.). Тело успешного ответа на запрос GET будет содержать запрашиваемый ресурс.
После того, как HTML страница была возвращена, она обрабатывается браузером. Далее браузер может исследовать ссылки на другие ресурсы (например, HTML страница обычно использует JavaScript и CSS файлы), и послать отдельный HTTP запрос на загрузку этих файлов.
Как статические, так и динамические веб-сайты (обсуждаемые в следующих разделах) используют точно такой же протокол / шаблоны связи.
Пример запроса / ответа GET
Вы можете сформировать простой GET запрос кликнув по ссылку или через поиск по сайту (например, страница механизма поиска). Например, HTTP запрос, посланный во время выполнения запроса "client server overview" на сайте MDN, будет во многом похож на текст ниже (он не будет идентичным, потому что части сообщения зависят от Вашего браузеранастроек.
Формат HTTP сообщения определен в веб-стандарте(RFC7230).Вам не нужно знать этот уровень детализации, но, по крайней мере, теперь Вы знаете откуда это появилось!
Запрос
Каждая строка запроса содержит информацию о запросе. Первая часть называется заголовок, он содержит важную информацию о запросе, точно так же как HTML head содержит важную информацию о HTML документе (но не содержимое документа, которое расположено в body):
Первая и вторая строки содержат большую часть информации, о которой говорилось выше:
- Тип запроса ( GET ).
- URL целевого ресурса ( /en-US/search ).
- Параметры URL ( q=client%2Bserver%2Boverview&topic=apps&topic=html&topic=css&topic=js&topic=api&topic=webdev ).
- Целевой вебсайт (developer.mozilla.org).
- Конец первой строки так же содержит короткую строку, идентифицирующую версию протокола ( HTTP/1.1 ).
Последняя строка содержит информацию о клиентских куки — в данном случае можно увидеть куки, включающие id для управления сессиями ( Cookie: session >).
Оставшиеся строки содержат информацию о используемом браузере и о его некоторых поддерживаемых возможностях Например, здесь Вы можете увидеть:
- Мой браузер ( User-Agent ) Mozilla Firefox ( Mozilla/5.0 ).
- Он может принимать информацию упакованную gzip ( Accept-Encoding: gzip ).
- Он может принимать указанные кодировки ( Accept-Charset: ISO-8859-1,UTF-8;q=0.7,*;q=0.7 ) и языков ( Accept-Language: de,en;q=0.7,en-us;q=0.3 ).
- Строка Referer идентифицирует адрес веб страницы, содержащей ссылку на этот ресурс (т.е. источник оригинального запроса, https://developer.mozilla.org/en-US/ ).
HTTP запрос так же может содержать body, но в данном случае оно пусто.
Ответ
Первая часть ответа на запрос показана ниже. Заголовок содержит информацию, описанную ниже:
- Первая строка содержит код ответа 200 OK , говорящий о том, что запрос выполнен успешно.
- Мы можем видеть, что ответ имеет text/html формат( Content-Type ).
- Так же мы видим, что ответ использует кодировку UTF-8 ( Content-Type: text/html; charset=utf-8 ).
- Заголовок так же содержит размер ответа ( Content-Length: 41823 ).
В конце сообщения мы видим содержимое body, содержащее HTML код возвращаемого ответа.
Остальная часть заголовка ответа содержит информацию об ответе (например, когда он был сгенерирован), сервере и о том, как он ожидает, что браузер обрабатывает страницу (например, строка X-Frame-Options: DENY говорит браузеру не допускать внедрения этой страницы, если она будет внедрена в на другом сайте).
Пример запроса / ответа POST
HTTP POST создается, когда вы отправляете форму, содержащую информацию, которая должна быть сохранена на сервере.
Запрос
В приведенном ниже тексте показан HTTP-запрос, сделанный, когда пользователь представляет новые данные профиля на этом сайте. Формат запроса почти такой же, как пример запроса GET , показанный ранее, хотя первая строка идентифицирует этот запрос как POST .
Основное различие заключается в том, что URL-адрес не имеет параметров. Как вы можете видеть, информация из формы закодирована в теле запроса (например, новое полное имя пользователя устанавливается с использованием: &user-fullname=Hamish+Willee ).
Ответ
Ответ от запроса показан ниже. Код состояния « 302 Found » сообщает браузеру, что сообщение удалось, и что он должен выдать второй HTTP-запрос для загрузки страницы, указанной в поле «Место». В противном случае информация аналогична информации для ответа на запрос GET .
Note: HTTP-ответы и запросы, показанные в этих примерах, были захвачены с использованием приложения Fiddler, но вы можете получить аналогичную информацию с помощью веб-снифферов (например, http://web-sniffer.net/ ) или с помощью расширений браузера, таких как HttpFox. Вы можете попробовать это сами. Используйте любой из связанных инструментов, а затем перейдите по сайту и отредактируйте информацию профиля, чтобы увидеть различные запросы и ответы. В большинстве современных браузеров также есть инструменты, которые отслеживают сетевые запросы (например, инструмент Network Monitor в Firefox).
Статические сайты
Статический сайт — это тот, который возвращает тот же жесткий кодированный контент с сервера всякий раз, когда запрашивается конкретный ресурс. Например, если у вас есть страница о продукте в /static/myproduct1.html , эта же страница будет возвращена каждому пользователю. Если вы добавите еще один подобный продукт на свой сайт, вам нужно будет добавить еще одну страницу (например, myproduct2.html ) и так далее. Это может стать действительно неэффективным — что происходит, когда вы попадаете на тысячи страниц продукта? Вы повторяли бы много кода на каждой странице (основной шаблон страницы, структуру и т. Д.), И если бы вы хотели изменить что-либо о структуре страницы — например, добавить новый раздел «связанные продукты» — тогда вы приходится менять каждую страницу отдельно.
Note: Статические сайты превосходны, когда у вас небольшое количество страниц, и вы хотите отправить один и тот же контент каждому пользователю. Однако они могут иметь значительную стоимость для поддержания, поскольку количество страниц становится больше.
Давайте вспомним, как это работает, снова взглянув на диаграмму архитектуры статического сайта, на которую мы смотрели в последней статье.

Когда пользователь хочет перейти на страницу, браузер отправляет HTTP-запрос GET с указанием URL-адреса его страницы HTML. Сервер извлекает запрошенный документ из своей файловой системы и возвращает ответ HTTP, содержащий документ, и код состояния HTTP Response status code of " 200 OK » (успех). Сервер может вернуть другой код состояния, например « 404 Not Found », если файл отсутствует на сервере или « 301 Moved Permanently », если файл существует, но был перенаправлен в другое место.
Серверу для статического сайта будет только нужно обрабатывать запросы GET, потому что сервер не сохраняет никаких модифицируемых данных. Он также не изменяет свои ответы на основе данных HTTP-запроса (например, параметров URL-адреса или файлов cookie).
Понимание того, как работают статические сайты, тем не менее полезно при изучении программирования на стороне сервера, поскольку динамические сайты обрабатывают запросы на статические файлы (CSS, JavaScript, статические изображения и т. д.) Точно так же.
Динамические сайты
Динамический сайт — это тот, который может генерировать и возвращать контент на основе конкретного URL-адреса запроса и данных (а не всегда возвращать один и тот же жесткий код для определенного URL-адреса). Используя пример сайта продукта, сервер будет хранить «данные» продукта в базе данных, а не отдельные файлы HTML. При получении запроса HTTP GET для продукта сервер определяет идентификатор продукта, извлекает данные из базы данных и затем создает HTML-страницу для ответа, вставляя данные в шаблон HTML. Это имеет большие преимущества перед статическим сайтом:
Использование базы данных позволяет эффективно хранить информацию о продукте с помощью легко расширяемого, изменяемого и доступного для поиска способа.
Использование HTML-шаблонов позволяет очень легко изменить структуру HTML, потому что это нужно делать только в одном месте, в одном шаблоне, а не через потенциально тысячи статических страниц.
Анатомия динамического запроса
В этом разделе представлен пошаговый обзор «динамического» цикла HTTP-запроса и ответа, основываясь на том, что мы рассмотрели в последней статье, с гораздо более подробной информацией. Чтобы «сохранить реальность», мы будем использовать контекст веб-сайта менеджера спортивной команды, где тренер может выбрать имя своей команды и размер команды в форме HTML и вернуться к предлагаемому «лучшему составу» для своей следующей игры.
На приведенной ниже диаграмме показаны основные элементы веб-сайта «team coach», а также пронумерованные ярлыки для последовательности операций, когда тренер обращается к списку «лучших команд». Части сайта, которые делают его динамичным, являются веб-приложением (так мы будем ссылаться на серверный код, обрабатывающий HTTP-запросы и возвращающие ответы HTTP), базу данных, которая содержит информацию об игроках, командах, тренерах и их отношения и HTML-шаблоны.
После того, как тренер отправит форму с именем команды и количеством игроков, последовательность операций:
- Веб-браузер создает HTTP-запрос GET на сервер с использованием базового URL-адреса ресурса ( /best ) и кодирования номера команды и игрока как параметров URL (например, /best?team=my_team_name&show=11) или как часть URL-адреса (например, /best/my_team_name/11/ ). Запрос GET используется, потому что запрос — только выборка данных (не изменение данных).
- Веб-сервер обнаруживает, что запрос является «динамическим» и пересылает его в веб-приложение для обработки (веб-сервер определяет, как обрабатывать разные URL-адреса на основе правил сопоставления шаблонов, определенных в его конфигурации).
- Веб-приложение определяет, что цель запроса состоит в том, чтобы получить «лучший список команд» на основе URL ( /best/ ) и узнать имя команды и количество игроков из URL-адреса. Затем веб-приложение получает требуемую информацию из базы данных (используя дополнительные «внутренние» параметры, чтобы определить, какие игроки являются «лучшими», и, возможно, также получить личность зарегистрированного тренера из файла cookie на стороне клиента).
- Веб-приложение динамически создает HTML-страницу, помещая данные (из базы данных) в заполнители внутри HTML-шаблона.
- Веб-приложение возвращает сгенерированный HTML в веб-браузер (через веб-сервер) вместе с кодом состояния HTTP 200 («успех»). Если что-либо препятствует возврату HTML, веб-приложение вернет другой код — например, «404», чтобы указать, что команда не существует.
- Затем веб-браузер начнет обрабатывать возвращенный HTML, отправив отдельные запросы, чтобы получить любые другие файлы CSS или JavaScript, на которые он ссылается (см. шаг 7).
- Веб-сервер загружает статические файлы из файловой системы и возвращает их непосредственно в браузер (опять же, правильная обработка файлов основана на правилах конфигурации и сопоставлении шаблонов URL).
Операция по обновлению записи в базе данных будет обрабатываться аналогичным образом, за исключением того, что, как и любое обновление базы данных, HTTP-запрос из браузера должен быть закодирован как запрос POST .
Выполнение другой работы
Задача веб-приложения — получать HTTP-запросы и возвращать ответы HTTP. Хотя взаимодействие с базой данных для получения или обновления информации является очень распространенными задачами, код может делать другие вещи одновременно или вообще не взаимодействовать с базой данных.
Хорошим примером дополнительной задачи, которую может выполнять веб-приложение, является отправка электронной почты пользователям для подтверждения их регистрации на сайте. Сайт также может выполнять протоколирование или другие операции.
Возвращение чего-то другого, кроме HTML
Серверный код сайта может возвращать не только HTML-фрагменты / файлы в ответе. Он может динамически создавать и возвращать другие типы файлов (текст, PDF, CSV и т. Д.) Или даже данные (JSON, XML и т. Д.).
Идея вернуть данные в веб-браузер, чтобы он мог динамически обновлять свой собственный контент (AJAX) существует довольно давно. Совсем недавно «Одностраничные приложения» стали популярными, где весь сайт написан с одним HTML-файлом, который динамически обновляется по мере необходимости. Веб-сайты, созданные с использованием этого стиля приложения, выталкивают множество вычислительных затрат с сервера на веб-браузер и могут привести к тому, что веб-сайты, ведут себя больше как нативные приложения (очень отзывчивые и т. д.).
Веб-структуры упрощают веб-программирование на стороне сервера
Веб-фреймворки на стороне сервера делают код записи для обработки описанных выше операций намного проще.
Одной из наиболее важных операций, которые они выполняют, является предоставление простых механизмов для сопоставления URL-адресов для разных ресурсов / страниц с конкретными функциями обработчика. Это упрощает сохранение отдельного кода, связанного с каждым типом ресурса. Он также имеет преимущества в плане обслуживания, поскольку вы можете изменить URL-адрес, используемый для доставки определенной функции в одном месте, без необходимости изменять функцию обработчика.
Например, рассмотрим следующий код Django (Python), который отображает два шаблона URL для двух функций просмотра. Первый шаблон гарантирует, что HTTP-запрос с URL-адресом ресурса /best будет передан функции с именем index() в модуле views. Запрос, который имеет шаблон « /best/junior », вместо этого будет передан функции просмотра junior() .
Note: Первые параметры в функциях url() могут выглядеть немного необычно (например, r’^junior/$’ потому что они используют метод сопоставления шаблонов под названием «регулярные выражения» (RegEx или RE). Вам не нужно знать, как работают регулярные выражения на этом этапе, кроме того, что они позволяют нам сопоставлять шаблоны в URL-адресе (а не жестко закодированные значения выше) и использовать их в качестве параметров в наших функциях просмотра. В качестве примера, действительно простой RegEx может говорить «соответствовать одной заглавной букве, за которой следуют от 4 до 7 строчных букв».
Веб-инфраструктура также упрощает функцию получения информации из базы данных. Структура наших данных определяется в моделях, которые являются классами Python, которые определяют поля, которые должны храниться в базовой базе данных. Если у нас есть модель с именем Team с полем «team_type», мы можем использовать простой синтаксис запроса, чтобы вернуть все команды, имеющие определенный тип.
В приведенном ниже примере представлен список всех команд, у которых есть точный (с учетом регистра) team_type «junior» — обратите внимание на формат: имя поля ( team_type ), за которым следует двойной знак подчеркивания, а затем тип соответствия для использования (в этом случае точное ). Существует много других типов совпадений, и мы можем объединить их. Мы также можем контролировать порядок и количество возвращаемых результатов.
После того, как функция junior() получает список младших команд, она вызывает функцию junior() , передавая исходный HttpRequest , HTML-шаблон и объект «context», определяющий информацию, которая должна быть включена в шаблон. Функция render () — это функция удобства, которая генерирует HTML с использованием контекста и HTML-шаблона и возвращает его в объект HttpResponse .
Очевидно, что веб-фреймворки могут помочь вам в решении многих других задач. В следующей статье мы обсудим намного больше преимуществ и некоторые популярные варианты веб-фреймворков.
Резюме
На этом этапе вы должны хорошо ознакомиться с операциями, которые должен выполнять серверный код, и знать некоторые способы, с помощью которых веб-среда на стороне сервера может сделать это проще.
В следующем модуле мы поможем вам выбрать лучшую веб-платформу для вашего первого сайта.


Отправить ответ